十字路口——容器的选择与取舍
起
最近上班路上习惯性看掘金和MySQL, 看掘金的时候经常看到一种文体:
“别再用Docker啦”, “Docker已经Out啦”, “K8S底层弃用Docker, 赶快换了吧”.
一般情况下我还是挺有战略定力的, 能够自动屏蔽这种近乎标题党的技术博客. 因为其内容大多都质量低下, 信息密度过低. K8S底层不用Docker了我倒是早有耳闻, 当时只是知道Docker不够好, 但是不知道具体哪里不好. 不过隔三差五的推送还是让我产生了”Docker是否仍然是我的最佳实践”的怀疑. 且越来越想点进去看看怎么个事儿. 终于, 在某一个下午, 我实在受不了诱惑, 点进了一篇博客. 至此, 一场持续近半周的反复试错开始了(手咋那么贱呐😭)
点击去之后, 发现大家都在说Podman这个东西, 号称解决了Docker的各种问题, 且与Docker保持超高兼容性, 甚至可以alias docker=podman而不出现问题.
Docker的问题
既然Podman解决了Docker存在的问题, 那么我们首先梳理一下现在的Docker存在些什么问题.
说实话, 在点进文章之前, 我在日常开发和部署场景中对Docker比较满意, 基本没发现存在什么问题. (看了Docker的缺点之后就受不了了(🤡👈))
Daemon守护进程
我愿将Daemon守护进程称之为Docker其他缺点的万恶之源, Docker的大部分缺点都是由于Daemon的设计而导致的.
那么什么是守护进程呢? 一个简单通俗易懂的版本是:
绝大部分采用C/S架构的, 不直接面向用户服务的, 通过systemd管理的service都是守护进程
守护进程有如下特点:
- 长期后台运行. 通常随着系统启动而启动, 运行期间不退出, 直到被手动停止.
- 独立于用户会话. 用户的登录, 注销, 关闭终端窗口不会影响守护进程的运行.
- 通常提供被动服务或监控. 通常处于”监听”或”睡眠”状态, 等待某个事件或请求发生才会被唤醒, 执行相关操作.(很像HTTP服务端)
- 通常提供系统级的服务. 它执行的往往是系统级的, 全局的任务. 通常以特权用户或专门指定的用户身份运行.
接下来再讲讲守护进程的创建过程, 以此来更深入的理解守护进程.(涉及到的东西太多, 先不忙看了, 后面单开一个文章单独介绍😋)
Docker也是有守护进程的, 就像一个HTTP服务器一样, 监听着Docker CLI发送的命令, 管理着Docker功能的具体实现.

可以看到, Docker Engine会去调用containerd(也是一个守护进程), containerd又会去调用runc.

为什么要套这么多层, 这就涉及到历史问题了. 让Gemini帮我写了一个发展历程, 放在最后了, 可以去[了解一下](#附录: containerd的由来)(Gemini真好用🤪)
那么Docker的守护进程有什么缺点呢?
Dockerd必须以root身份运行, 如果容器内使用root用户且挂载了宿主机关键目录, 则会导致容器内部可以对宿主机造成影响, 从而威胁宿主机(比如在/root/.ssh/下放置自己的公钥等).Dockerd功能过于全面, Dockerd出现问题, 则容器, 网络, 构建等Docker功能都无法使用. 举个例子, Docker容器的开机自启是通过Dockerd拉起来的, 即Systemd启动Docker, Docker又将自己需要开机自启的容器给拉起来. 如果Docker出现问题, 则容器也无法实现开机自启.
那么问题来了, 为什么Docker需要守护进程呢? 就算需要, 那sshd也是守护进程, 为什么它就没有被骂呢?
这个问题还得从功能性上说起. sshd从功能上来说只起一个”门卫”的作用. 仅仅是用户发起ssh请求的时候, sshd负责鉴权和连接建立. 只要ssh连接建立完毕, sshd就功成身退. 也就是说, 就算sshd宕机, 也不会影响已经建立的ssh连接, 只是不能建立新的ssh连接而已.
而Docker则不同, Docker里面存在大量的系统敏感操作以及状态监控.
- 比如Docker容器的建立过程中, 涉及到network的建立与修改, 本地路径的绑定以及端口的绑定.(如果绑定的是1024以下的端口号则必须要root权限)
- Docker容器状态的监控. 如果没有守护进程, 那么Docker创建容器后变会失去对容器的掌控(因为没有守护进程的话Docker创建好容器后, 父进程就退出了), 无法正常监控/修改Docker容器的状态.
所以, 从Docker的实际需要上来说, 还是需要一个守护进程的. 茂然取消守护进程, Docker的现有功能都将无以为继.
K8S的区别
K8S的重点在集群部署和资源分配, 涉及到跨机器的网络服务以及其他的增强功能, 所以与Docker Daemon的功能存在重叠与冲突, 原来K8S使用Docker-shim来控制Dockerd, 但是这样对Docker存在着严重的依赖, 因为Docker功能/接口的修改, 导致K8S不得不一直去主动修改Docker-shim以适配Docker的变化. 随后, K8S底层弃用了Docker Daemon, 直接从kubelet控制containerd, 随之带来的是性能上的提升与架构上的精简.
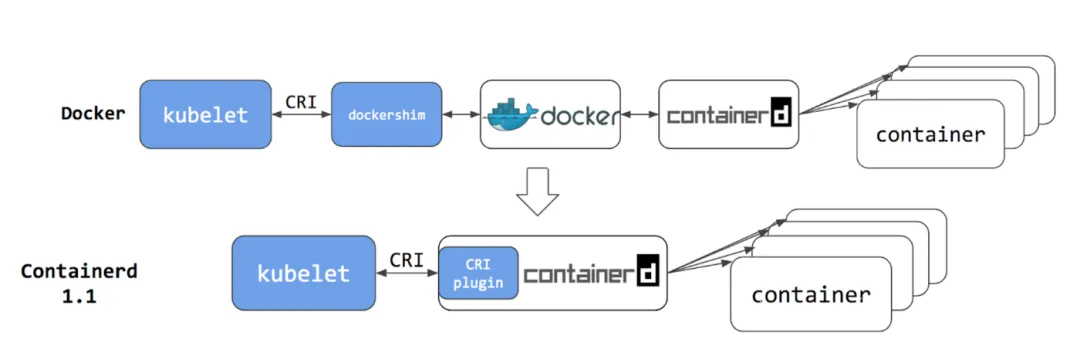
NOTE需要注意的是, K8S并没有解决上述Docker的缺点, 因为containerd也是一个守护进程, 也必须要以root权限运行, 所以从根本上来说, K8S存在和Docker一样的缺陷. 但是K8S通过各种措施(权限分散, 例如有专门管理网络的守护进程, 禁止容器内以root用户运行, 禁止挂载关键目录等)来将上述缺陷带来的影响降到最小.
承
说完了Docker的缺点, 接下来我们该看看号称解决了上述缺点的Podman如何了.
从架构上来说, Podman采用无守护进程的设计, 这从根本上就杜绝了上述Docker的缺点. 但是随之而来的, Podman要想办法补足因为缺少守护进程而带来的功能缺失.
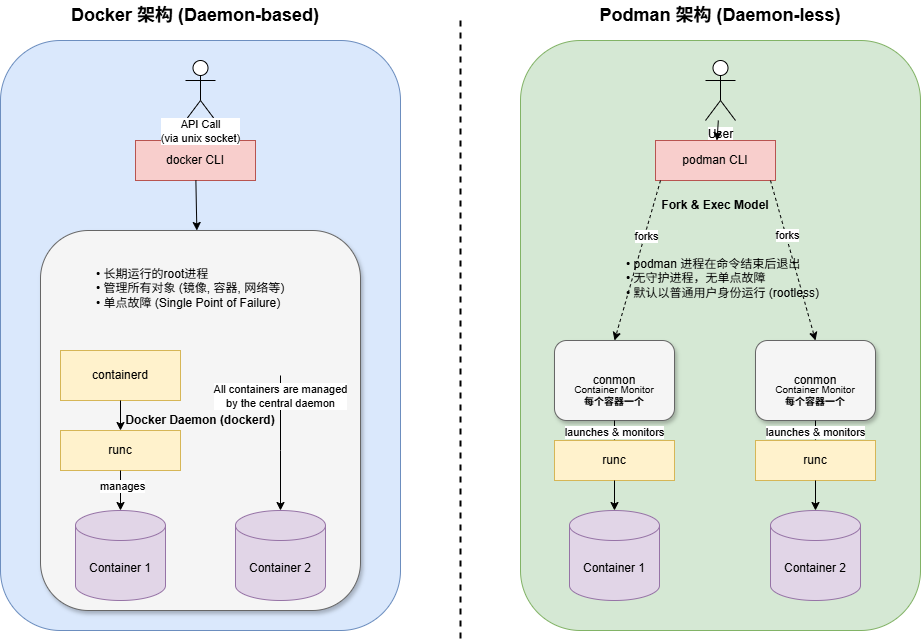
- 图中的
conmon是一个监控进程, 用于当做具体的Container的父进程,以实现对接CLI, 满足podman ps等命令的需求. - 以fork/exec创建进程, 而非通过一个守护进程管理. 这样的话容器更加透明, 可以被纳入systemd管理, 控制容器的开机自启等.
- 默认以
rootless默认运行, 避免了权限集中. 在rootless模式下, 容器内的root操作会经过”用户命名空间”转换为当时执行podman run命令, 从而避免了”权限泄露”.
不仅如此, Podman还支持Pod功能(同K8S中的Pod). Pod最吸引我的一点就是Pod可以把多个容器放在同一个网络空间下. 对比compose的不同体现在:
- compose中每个容器拥有自己的网络命名空间, 每个容器都可以使用相同的端口(只要不绑定同一个宿主机端口即可). 容器之间的访问是通过”hostname”的. 即Java容器访问Redis, 在地址上填写的应该是
docker-compose.yml中Redis容器的名称. Docker会将容器的name设置为容器的hostname. - pod中每个容器共享一个网络命名空间. 这也就意味着, 一个容器只要占用了8080, 其它容器就不能够占用了. 容器之间的访问也是直接使用
localhost.
有了Pod功能, 我就可以不用维护一个单独的deploy分支, 而deploy分支仅仅只是修改了地址(我居然忘记了application.yml可以设置不同active, 如dev, prod😭)
既然有了Pod, 那么一个Pod能不能打成一个镜像呢? 因为我最近正好有这个需求, 需要用Java把Python算法层包起来打成一个镜像. 结果是不能. 令人遗憾的
转
既然podman这么好, 那么我们直接开用吧!
打开Google开始搜索, 进入官网点击下载一看, 布豪! 是Desktop
曾经多少个夜里, 受到Docker Desktop的折磨. 启动慢, 有时候一更新就启动不起来, 只能重装Docker Desktop. 看到Podman Desktop, 多少有点犯怵.
于是, 怀着忐忑的心情, 终究还是下载了.
安装之后一看: 典中典Desktop行为. 在我的电脑里新增了一个WSL, 一个叫podman-machine-default, 用来放podman实例.

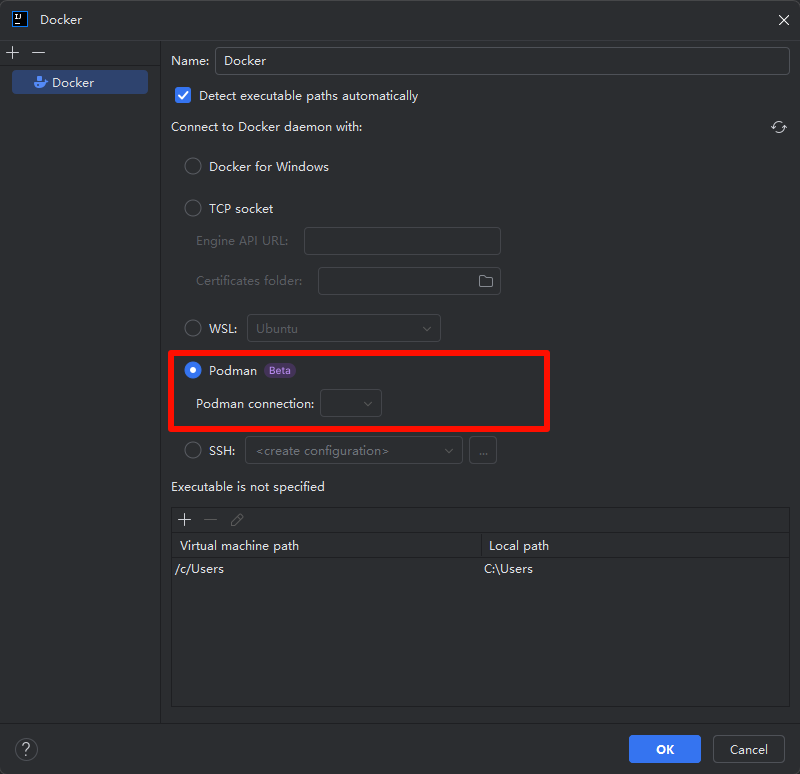
虽然这种方式能保持比较好的兼容性, 但是很不优雅,和Podman Desktop绑定的太严重了. podman-machine-default是靠Podman Desktop启动的, 所以如果Podman Desktop的开机自启或者其他什么出了问题, podman功能也会受到影响. 这样的话岂不是又回到Docker Desktop的年代了. 这可不行, 我得去找一个更加优雅的方式.
优雅的代价
参考彻底摆脱docker-desktop的Docker处理方式, Podman也应该是我们自己在WSL里面安装和管理. 所以我们尝试在WSL里面进行安装
// 1. 安装podman
sudo apt install podman -y
// 2. 设置镜像源
sudo vim /etc/containers/registries.conf
// 3. 配置全局alias docker=podman但是安装完之后出现了一个致命的问题: IDEA选择Ubuntu, 但是构建镜像一直会出现(EOF)
这个问题太致命辣😭, 导致无法正常使用podman, 因为在WSL里面, 如果要自己处理的话, 还需要考虑文件的传输与映射…
rootless之殇
但是, 刨开以上安装问题, rootless本身有什么缺点呢?
网络IO损耗.
在
root下, 网络IO的数据流转路径为:容器 -> 内核(veth) -> 内核(bridge) -> 内核(iptables/NAT) -> 物理网卡整个数据包转发、处理、NAT 的过程几乎完全在内核空间完成, 效率非常高.
而在
rootless下, 网络IO的数据流转路径则为:容器 -> 内核(tap设备) -> slirp4netns进程(用户空间) -> 内核(主机协议栈) -> 物理网卡每个网络数据包都必须在内核空间与用户空间之间来回复制和切换, 这使得整个上下文切换的开销非常大.
文件IO损耗.
场景 I/O 路径 性能对比 A. Rootful + 卷 (e.g., sudo podman ... -v)App -> Kernel -> Host FS最佳性能(基准) B. Rootless + 卷 (e.g., podman ... -v)App -> Kernel (with UID map) -> Host FS性能极接近A。损失来自于可忽略的UID映射。 C. Rootless + 无卷 (数据在可写层) App -> Kernel -> fuse-overlayfs (Userspace) -> Kernel -> Host FS性能最差。承受了CoW和FUSE的双重打击。 D. Rootful + 无卷 (数据在可写层) App -> Kernel (overlayfs) -> Host FS性能较差。承受了CoW的打击。
rootless的podman, 在我看来, 是向”虚拟机”前进了一步, “容器”的味道更淡了, 因为容器内的所有操作都经过用户空间的程序进行”代理” . 而又因为没有守护进程, 所以就算是root类型的podman, 命令只在你执行它的那一瞬间拥有 root 权限。一旦命令结束,特权进程就消失了。攻击者必须在你恰好执行 sudo podman 命令的毫秒级窗口内,通过某种方式劫持该进程,这比攻击一个 24/7 监听的 API 难上无数个数量级。风险是短暂的、瞬时的
合
愿你刷机半生, 归来仍是
MIUI(Docker)🤣
看似上面写了这么多, 实则不及我实际尝试的1/5的内容. 一把辛酸泪啊
我还是回到了Docker的怀抱, 虽然他有那么多的”缺点”, 但是我还是最熟悉他, 且现在我也没有具体感知到它的缺点. Podman虽然有这么多优点, 但是在Windows环境下还是有这么多”不优雅”的问题. 且使用rootless模式的话对网络IO损耗很大. 后续找时间可以单独测一下rootless的网络IO损耗, 以正式确定对日常开发及建议部署上的影响.
不过, 还是得要勇于尝试新事物呢

附录: containerd的由来
简单来说:containerd 的由来,本质上是 Docker 为了响应行业对标准化的需求,将自己内部的核心容器管理功能“剥离”出来,形成的一个独立、开放的项目,并最终捐赠给了中立基金会,成为了整个容器生态系统的核心基石。
第一阶段:Docker 的“大单体”时代 (The Monolith)
在 2013-2015 年,Docker 席卷了整个技术圈。当时的 Docker 守护进程(dockerd)是一个巨大的“一体化”程序,它几乎无所不能:
- CLI 交互:接收
docker run,docker build等命令。 - API 服务:提供远程 API。
- 镜像构建:负责
Dockerfile的解析和镜像构建。 - 镜像管理:负责镜像的拉取、推送和存储。
- 存储管理:管理容器的存储卷(Volume)。
- 网络管理:创建和管理容器网络。
- 容器执行:真正运行容器(当时使用的是一个叫
libcontainer的内置库)。
问题来了:这个“大单体”架构虽然功能强大,但也带来了几个严重的问题:
- 过于臃肿:任何一个小改动都可能影响到整个庞大的系统,维护和升级困难。
- 绑定过深:像 Kubernetes、Mesos 这样的编排工具,如果想运行容器,就必须依赖并集成整个 Docker Daemon。但它们其实只需要最核心的“运行和管理容器”功能,并不需要镜像构建或复杂的 Docker 网络功能。
- 厂商锁定风险:整个生态都依赖于 Docker 公司维护的这一个软件,不利于形成一个开放、健康的生态系统。
第二阶段:标准化与 runc 的诞生
为了解决生态系统碎片化和厂商锁定的问题,2015年,Docker 联合 CoreOS、Google 等公司共同发起了 OCI(Open Container Initiative) 开放容器倡议。
OCI 的目标是制定两个核心标准:
- 运行时标准 (Runtime Spec):定义了如何运行一个容器。
- 镜像格式标准 (Image Spec):定义了容器镜像应该是什么样的。
为了支持这个标准,Docker 将其内部的容器运行库 libcontainer 提取出来,并围绕 OCI 运行时标准进行封装,创建了一个独立的、小巧的命令行工具——runc。
runc 的诞生是解耦的第一步:将最底层的“容器执行”部分标准化并独立出来。
此时的架构变成了: Docker Daemon -> (调用) -> runc
第三阶段:核心功能的分离,containerd 诞生
虽然 runc 解决了“如何运行”的问题,但 Docker Daemon 依然掌管着镜像、存储、网络等一系列高级管理功能。对于 Kubernetes 来说,Docker Daemon 还是太“重”了。
为了让 Docker 的核心技术能被更广泛地采用,并进一步推动模块化,Docker 公司做出了一个重大决定:
在 2016 年,他们将 Docker Engine 中所有与容器生命周期管理相关的核心功能(除了 runc 的部分)再次剥离出来,形成了一个新的独立组件,并将其命名为 containerd。
containerd 的初始职责包括:
- 管理容器的整个生命周期(创建、启动、停止、删除)。
- 镜像的拉取、存储和分发。
- 管理容器网络和存储。
- 通过调用
runc来实际执行容器。
这样一来,Docker Daemon 自己也变成了一个 containerd 的客户端。整个架构变得更加清晰和分层:
演进过程:
- 旧架构:
Docker CLI->Docker Daemon (大单体) - 引入runc后:
Docker CLI->Docker Daemon->runc - 引入containerd后:
Docker CLI->Docker Daemon->containerd->runc
第四阶段:捐赠给 CNCF,成为行业标准
为了彻底消除社区对于 Docker 公司控制 containerd 的疑虑,使其成为一个真正中立的行业标准,Docker 公司在 2017 年做出了最关键的一步:
将 containerd 项目捐赠给了 CNCF(Cloud Native Computing Foundation,云原生计算基金会)。
CNCF 是一个中立的基金会,旗下管理着 Kubernetes、Prometheus 等众多成功的开源项目。这一举动意义重大:
- 中立治理:
containerd不再属于任何一家公司,而是由整个社区共同治理,确保了其开放性和公正性。 - 与 Kubernetes 深度集成:Kubernetes 项目开发了 CRI(Container Runtime Interface,容器运行时接口),这是一个标准化的插件接口,允许
kubelet与任何兼容的容器运行时进行通信。containerd迅速实现了 CRI,使得 Kubernetes 可以直接与containerd对话,完全绕过 Docker Daemon。
- 这就是为什么在现代 Kubernetes 集群中,
containerd是首选的运行时,并且 Kubernetes 最终宣布弃用 Docker-shim(即通过 Docker Daemon 与容器运行时交互的旧方式)。