Netty 学习:事件循环与多线程
Netty与多线程学习
Netty 的学习曲线较为陡峭, 涉及大量细节设计与并发模型. 本文将记录从初步理解到深入源码的探索过程, 重点分析学习过程中遇到的思维误区与认知纠偏. 记录这些”错误认识”对于理解 Netty 的设计初衷往往更具价值.
Netty初印象
其实之前学过Netty, 也大概知道Netty的优势, 这次主要带着学习语法, 深入细节的目的来看的. 最开始对Netty的了解无非是:
- 有个EventLoop事件循环, 里面有一个线程, run命令不断运行着select(), 且处理各种事件.
- 经典多Reactor架构, 主Reactor负责
ServerSocketChannel和处理accept事件, 并将accept得到的SocketChannel注册到子Reactor中, 具体的读写事件等由子Reactor负责
总结起来就是下面这个图
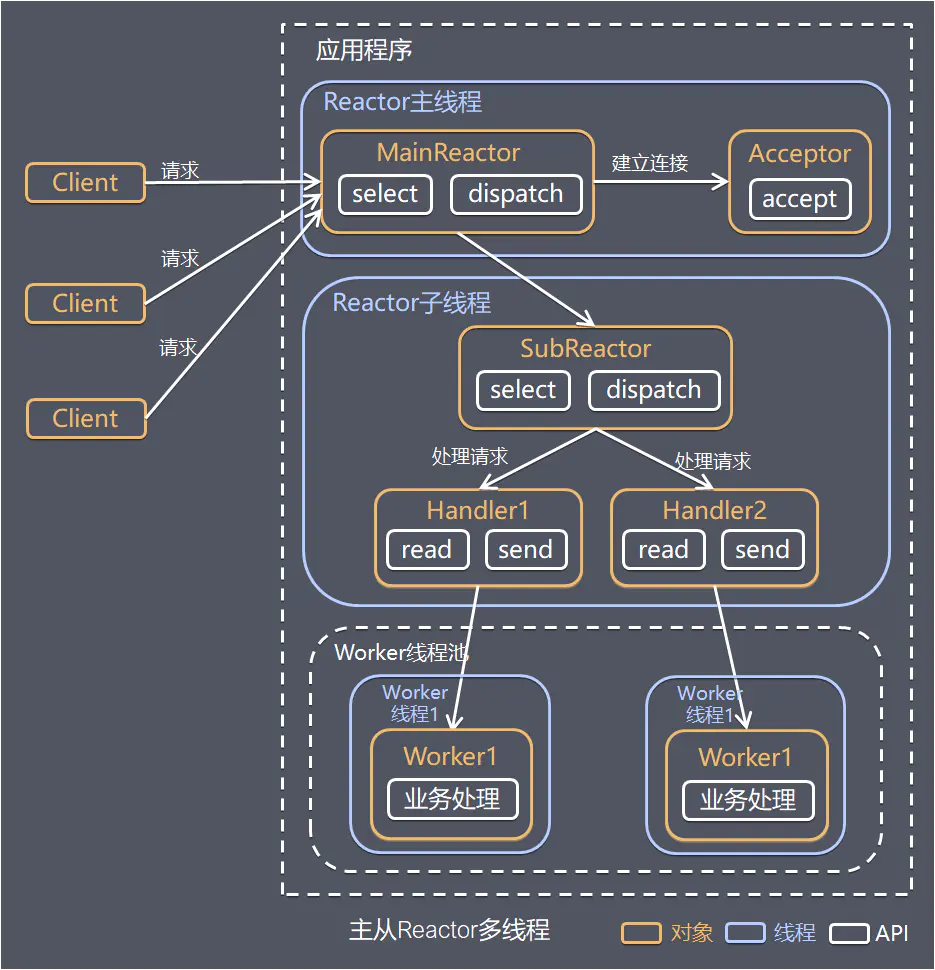
不过需要说明的是, 我这个时候还没有意识到”Worker”线程池在Netty中的存在形式和意义.
理解到这里, 如果仅仅是写一些基础的小demo, 已经完全够了, 直到我看视频看到了taskQueue
taskQueue 的出现
单独看taskQueue是很正常的, 就是寻常的executorService配上对应的Runnable的任务队列嘛. 但是视频里使用的操作是:
ctx.channel().eventloop().submit();我自己尝试的时候, 发现了还有这么一个方法:
ctx.executor();本来到这里的时候, 还没有这么懵, 心里想的是, 可能跟ssc.socket().bind()/ssc.bind()那样, 一个是老的写法, 一个是新的写法, 是等价的. 不过视频又说:
费时的任务必须要通过在其他线程进行, 提交出去, 不然的话会阻塞事件循环
于是, 我追了一下这个executor()的代码, 发现了不对劲的地方.
public final EventExecutor executor() {
if (invoker == null) {
return channel().eventLoop();
} else {
return wrappedEventLoop();
}
}此时通过调试发现 invoker 确实是 null, 这意味着 executor() 返回的就是 channel().eventLoop(). 这里出现了一个显著的矛盾点: 如果直接使用 eventLoop 执行耗时任务, 必然会阻塞 I/O 线程 (因为 submit 的任务和事件循环运行在同一个线程). 为了验证我的猜想, 我开始去搜索事件循环的源码.
protected void run() {
boolean oldWakenUp = wakenUp.getAndSet(false);
try {
if (hasTasks()) {
// 有任务的话非阻塞的处理现有的事件
selectNow();
} else {
// 之前设置了下次任务的触发时间, select的话最多等待oldWakenUp的事件就返回, 避免影响任务的运行
select(oldWakenUp);
if (wakenUp.get()) {
selector.wakeup();
}
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
// 处理事件
processSelectedKeys();
// 处理自定义任务
runAllTasks();
} else {
final long ioStartTime = System.nanoTime();
// 处理事件
processSelectedKeys();
final long ioTime = System.nanoTime() - ioStartTime;
// 处理自定义任务
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
cleanupAndTerminate(true);
return;
}
}
} catch (Throwable t) {
logger.warn("Unexpected exception in the selector loop.", t);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Ignore.
}
}
scheduleExecution();
}从源码可见, 任务确实在同一个线程内串行执行, 这证实了阻塞的风险. 那么视频中提到的”必须提交到其他线程执行以避免阻塞”, 其背后的实现机制究竟是什么?
ChannelHandlerContext与ChannelHandlerAdapter
最开始写pipeline时, 直觉会把它当成”handler链”. 因为写代码的入口就是:
pipeline.addLast(new LoggingHandler());
pipeline.addLast(new BizHandler());但是如果去翻看源码, 就会发现一个问题: pipeline里到底存的是什么? addLast 到底把我们的 handler 放到哪里去了?
点进去看 DefaultChannelPipeline 的源码:
@Override
public ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
synchronized (this) {
name = filterName(name, handler);
addLast0(name, new DefaultChannelHandlerContext(this, findInvoker(group), name, handler));
}
return this;
}这里非常关键的一步是 new DefaultChannelHandlerContext(..., handler). Pipeline并没有直接把handler存进链表, 而是先用 Context 把它”包了一层”. 再看一下 addLast0 的实现:
private void addLast0(final String name, AbstractChannelHandlerContext newCtx) {
checkMultiplicity(newCtx);
AbstractChannelHandlerContext prev = tail.prev;
newCtx.prev = prev;
newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx;
name2ctx.put(name, newCtx);
callHandlerAdded(newCtx);
}这就很清楚了: Pipeline的双向链表里, 真正连接的节点是 Context, 不是 Handler. addLast 的核心逻辑就是创建一个 Context 对象 (包裹了 handler 和 invoker), 然后把它挂载到 tail 节点的前面.
这时候再回头看 AbstractChannelHandlerContext 的结构, 感觉就不一样了:
abstract class AbstractChannelHandlerContext implements ChannelHandlerContext {
// 链表指针
volatile AbstractChannelHandlerContext next;
volatile AbstractChannelHandlerContext prev;
// 核心成员
private final ChannelHandler handler; // 具体的逻辑实现 (用户写的)
private final DefaultChannelPipeline pipeline; // 归属管道
private final ChannelHandlerInvoker invoker; // 执行器 binding (注: Netty 5/部分版本为invoker, 4.1为executor)
}思考过程的转变:
- 直觉: Pipeline是一个
List<Handler>. - 代码事实:
addLast的时候,new DefaultChannelHandlerContext把handler包起来了, 然后把ctx连到了链表上. - 结论:
Context才是骨架,Handler只是被骨架拿着的”具体业务逻辑”.
这也解释了为什么事件传播 (fireChannelRead) 是 ctx.fire... 驱动的:
public ChannelHandlerContext fireChannelRead(Object msg) {
// 找到下一个节点 (Context)
invokeChannelRead(findContextInbound(), msg);
return this;
}
static void invokeChannelRead(AbstractChannelHandlerContext next, Object msg) {
// 获取节点绑定的执行器
EventExecutor executor = next.executor();
// 决定是在当前线程跑, 还是提交任务
if (executor.inEventLoop()) {
next.handler().channelRead(next, msg);
} else {
executor.execute(() -> next.handler().channelRead(next, msg));
}
}Context 在这里起到了”调度员”的作用:
- 它知道上一个节点是谁, 下一个节点是谁 (
next/prev). - 它知道这个 handler 应该在哪个线程跑 (
executor). - 它知道怎么去调用 handler (
next.handler().channelRead).
如果只存 handler, 这里的”上下文信息” (线程, 位置, 管道引用) 就没地方放了. 这就是 Context 存在的意义: 它是Handler在Pipeline中的运行环境包装.
ChannelInboundHandlerAdapter 这类adapter在这里的定位也更明确. 它解决的是handler实现的便利性, 给出默认空实现. ctx解决的是运行时语义, 节点, 调度, 传播. 这两者不在一个层级上.
ctx这条线理顺之后, 再回头看 ctx.executor() 就不再是”拿个executor用一下”, 而是”这个节点的回调应当落在哪个执行器上”. 于是 invoker != null 对应的执行器来源需要继续追.
EventExecutorGroup与child executor
ctx.executor()里那段分支逻辑背后, 关键入口是pipeline添加handler时是否带EventExecutorGroup. 典型写法如下:
EventExecutorGroup bizGroup = new DefaultEventExecutorGroup(8);
pipeline.addLast(bizGroup, "bizHandler", new BizHandler());这里再次回到 addLast 的源码, 其中的 findInvoker(group) 就变得很有深意了:
// addLast 内部逻辑
EventExecutorInvoker invoker = findInvoker(group);
new DefaultChannelHandlerContext(this, invoker, name, handler);当传入了 bizGroup 时, invoker 就不是 null 了, 而是从 bizGroup 里选出来的一个 EventExecutor (也就是所谓的 child executor).
这里必须要通过源码理清”Group”和”Executor”的物理结构关系 (Deduced directly from source):
宏观结构 (EventExecutorGroup): 它持有核心的线程资源池. 在默认情况下 (
new DefaultEventExecutorGroup), 它内部持有一个ForkJoinPool(或者用户指定的其他 Executor).// MultithreadEventExecutorGroup 简化结构 private final Executor executor; // 这里通常是 ForkJoinPool private final EventExecutor[] children; // 孩子节点数组微观结构 (SingleThreadEventExecutor): 每一个 child (EventExecutor) 都是一个独立的任务执行器. 它自己持有一个
thread变量.// SingleThreadEventExecutor 简化结构 private volatile Thread thread; // 它的"御用"线程启动与绑定: 当第一个任务提交给 child 时, child 会委托 Group 的
executor(ForkJoinPool) 去执行它的run方法. 一旦 ForkJoinPool 的某个 worker 线程开始执行这个run, child 就会抓住这个线程:this.thread = Thread.currentThread(). 从此, 这个 worker 线程就成了这个 child 的”御用 IO/业务线程”.
理解了这个结构后, 我们再看 AbstractChannelHandlerContext.executor() 的实现:
@Override
public EventExecutor executor() {
if (invoker == null) {
// 如果没有绑定额外的 executor, 就用 channel 自己的 eventLoop
return channel().eventLoop();
} else {
// 如果绑定了, 就返回绑定的那个 (也就是上面说的那个 child)
return invoker.executor();
}
}把这个逻辑代入回 invokeChannelRead 的场景:
static void invokeChannelRead(AbstractChannelHandlerContext next, Object msg) {
// 1. 这里拿到的 executor 是 bizGroup 里的某个 child
EventExecutor executor = next.executor();
// 2. 当前线程是 I/O 线程 (Channel 的 EventLoop)
// 3. executor.inEventLoop() 实际上在问: "Channel的线程 == Child的那个御用线程" ?
if (executor.inEventLoop()) {
next.handler().channelRead(next, msg);
} else {
// 4. 显然不相等 (false), 于是进入 else, 提交任务!
executor.execute(() -> next.handler().channelRead(next, msg));
}
}这一步推导就把视频里那句”费时任务要提交到其他线程”落到一个具体机制上了: 不是把耗时逻辑丢给eventLoop的taskQueue(那样还是会卡死IO), 而是让handler对应的 Context 绑定到一个独立的 executor 上. 当 I/O 线程传播事件到这个 Context 时, 发现 ctx.executor() (Child的线程) 不是自己 (IO线程), 于是自然而然地通过 else 分支把任务 submit 到了那个独立的 executor 去执行.
这也自然引出一个新的关注点: executor和eventLoop在类型体系里看起来很像, 都能submit, 都能schedule. 但它们的职责边界不同. eventLoop承载channel的线程归属和I/O驱动, child executor只承载某些handler节点的业务执行.
既然知道了结构 (Group 有 Pool, Child 有 Thread), 下一个问题自然就是: Child 里的 Thread 是什么时候、怎么从 Pool 里拿到的? 这引导我们关注 SingleThreadEventExecutor.execute() —— 它是线程启动的触发点.
SingleThreadEventExecutor与线程启动 (解析线程启动时序)
要理解任务调度, 必须先解释清楚这个 Executor 到底是怎么”跑起来”的. 很多时候我们看源码容易陷入细节, 忘了上下文场景.
场景还原: 谁在调用 execute?
通常有两个典型时机:
- 启动时 (Main Thread): 当我们写
bootstrap.bind(8080)时, 主线程会一路调用到initAndRegister. 此时 Channel 需要注册到 EventLoop 上, 也就是调用eventLoop.execute(register_task).
- 此时上下文: 这里的
register_task就是那个 Runnable. 调用线程是Main Thread. - 状态: EventLoop (Child) 此时还没启动, 它的
thread字段是 null.inEventLoop()返回 false. - 触发: 必须立刻启动线程来处理这个注册任务!
- 运行时 (External Thread): 比如我们在一个业务线程池里调用
ctx.write("hello").
- 此时上下文:
write_task是 Runnable. 调用线程是BizThreadPool-Thread-1. - 状态: EventLoop 已经在运行了. 但调用者不是它自己.
inEventLoop()返回 false. - 触发: 只是把任务投递进去, 不用启动线程.
理解了这个场景, 再看 execute 的源码, 那个 else 分支的意义就非常具体了:
@Override
public void execute(Runnable task) {
if (task == null) throw new NullPointerException("task");
boolean inEventLoop = inEventLoop();
if (inEventLoop) {
addTask(task);
} else {
// 关键分支:
// 场景1 (启动时): 主线程进来, 发现 EventLoop 没跑, 于是 startExecution() -> 启动线程!
// 场景2 (运行时): 业务线程进来, 发现 EventLoop 在跑但不是我, 只是入队.
startExecution();
addTask(task);
// ... (拒绝策略处理)
}
// ... (唤醒逻辑)
}紧接着的问题是: startExecution 到底怎么把 Pool 里的线程变成自己的?
private void doStartThread() {
// 委托 Group 里的 executor (ForkJoinPool) 去执行
executor.execute(new Runnable() {
@Override
public void run() {
// 核心逻辑: 线程绑定
// ForkJoinPool 分配了一个 Worker 线程给我们
// 我们立刻把它抓住, 赋值给 this.thread
thread = Thread.currentThread();
try {
// 从此, 这个 Worker 线程与该 EventExecutor 完成绑定, 开始循环运行 EventLoop 的逻辑
SingleThreadEventExecutor.this.run();
} catch (Throwable t) {
logger.warn("Unexpected exception from an event executor: ", t);
}
}
});
}这里完成了关键的Binding (绑定): ForkJoinPool-1-worker-1 只是一个普通的通用线程, 但当它执行了这行代码后, 它就成为了该 EventLoop 的专属线程. 之后所有的 inEventLoop() 判断, 都是拿当前线程和这个 thread 做比较.
schedule与scheduledTaskQueue
搞清楚了”线程是谁”以及”怎么绑定的”, 再看定时任务 (schedule) 就顺畅多了. 这里的核心矛盾是: 如何保证线程安全?
查看 schedule 源码时, 我们会发现它并不是简单地把任务塞进队列:
<V> ScheduledFuture<V> schedule(final ScheduledFutureTask<V> task) {
if (inEventLoop()) {
scheduledTaskQueue().add(task);
} else {
// 如果是外部线程想安排定时任务 (比如在业务线程延时断开连接)
execute(new Runnable() {
@Override
public void run() {
// 必须封装成一个任务, 扔回 EventLoop 线程里执行 add
scheduledTaskQueue().add(task);
}
});
}
return task;
}这里的逻辑链条是:
scheduledTaskQueue(通常是 PriorityQueue) 不是线程安全的.- 为了避免加锁带来的性能损耗, Netty 决定只能由 EventLoop 绑定的那个专属线程来操作队列.
- 如果
inEventLoop()为假 (说明是外部线程), 就不能直接add. 必须调用execute(也就是我们上面分析的方法), 把”添加任务”这个动作本身封装成一个 Runnable, 投递过去.
Future原理与回调机制
任务能执行了, 定时任务也能排队了, 最后一个环节就是: 我们怎么知道任务做完了? 这就引出了 Netty 的 Future (或 Promise) 机制.
在 Java 原生 Future 里, 我们习惯用 get() 阻塞等待. 但在 Netty 的世界里, get() 往往是”不得已”的选择.
1. Future.get() 的本质: 阻塞等待
当我们调用 future.get() 时, 实际上是触发了 Monitor 模式 的等待:
// DefaultPromise 源码片段 (简化)
public V get() throws InterruptedException, ExecutionException {
await(); // 核心在这里
// ...
return result();
}
public Promise<V> await() throws InterruptedException {
synchronized (this) {
// 只要还没完成, 就一直 wait (释放锁, 挂起当前线程)
while (!isDone()) {
incWaiters();
try {
wait();
} finally {
decWaiters();
}
}
}
return this;
}这种模式在 Reactor 模式下是非常危险的. 如果你在 EventLoop 线程里调用了 future.get(), 而这个 future 又在等待 EventLoop 做完某件事, 就会直接导致死锁.
2. Listener 回调: 异步通知
所以 Netty 更推崇的是 Listener 模式. 它采用了 异步通知 机制, 而非同步等待.
public Promise<V> addListener(GenericFutureListener<? extends Future<? super V>> listener) {
synchronized (this) {
if (isDone()) {
notifyListener(listener);
} else {
// 未完成, 则添加到监听器列表
addListener0(listener);
}
}
return this;
}当结果产生时 (比如 trySuccess):
public boolean trySuccess(V result) {
synchronized (this) {
if (!setSuccess0(result)) return false;
notifyListeners(); // 遍历并回调监听器
}
return true;
}这里有一个隐性的连贯性: notifyListeners() 通常是由调用 setSuccess 的那个线程执行的. 如果这个 future 代表的是 I/O 操作 (如 writeAndFlush), 那么 setSuccess 的大概率是 EventLoop 线程. 这意味着: 你的 Listener 回调代码,也是在 EventLoop 线程里跑的.
这也解释了 Netty 最佳实践里的一条重要原则: 严禁在 Listener 中执行耗时操作, 否则你会卡住整个 I/O 线程, 导致后面所有的请求都进不来.
总结全篇: 从 Pipeline 的骨架结构, 到 Group 提供的线程池资源; 从 execute 时的懒启动和线程绑定, 到 schedule 时的线程安全保护, 最后到 Future/Promise 的异步通知网络. 这一整套逻辑环环相扣, 共同构成了 Netty 高效运转的内在逻辑.