UV在不同端的行为探讨
书接关于UV管理Python项目以及Docker打包的最佳实践探讨, 结尾观察到了Linux端和Windows端使用相同命令导致的不同依赖的问题. 本文尝试对其进行探讨, 尽可能的找到其稳定规律, 并形成后续使用的最佳实践.
初步困扰
首先就被一个比较棘手的问题给难住了. 为了严格地, 排除其他变量地复现这个现象, 需要有Linux端和Windows端的设备, 且他们都需要有GPU, 而WSL共享的是Windows的驱动, 所以也不是真正意义上的Linux环境. 这意味着使用VMWare/VirtualBox等开虚拟机是不能够支持GPU加速的, 也就是说我需要一个完整的Linux/Windows环境才可以进行尝试. 但是我现在的几台电脑无法支持我进行系统重装(东西太多太麻烦了).
不过后续想到了使用Colab/Kaggle平台进行尝试. 使用uv的话应该能够拥有一套完整的Linux环境.
Kaggle环境尝试
说干就干, 使用Kaggle开一个notebook, 启用GPU之后使用find查找一下之前说的libcublas.so.*库存不存在.
find /* -name libcublas.so.*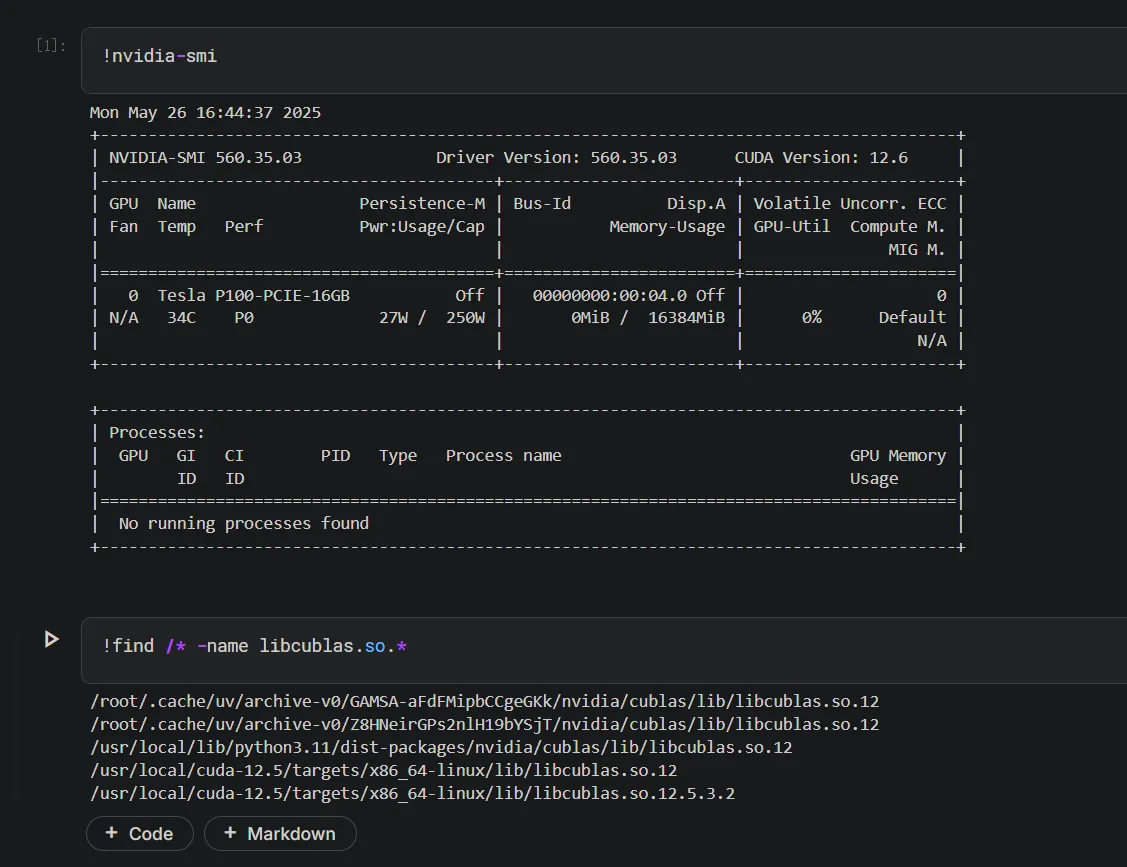
可以看到是有相关库的(而且似乎Kaggle的环境管理就是用的uv🤣). 这与我们的预期不符, 我们期望的应该没有的情况(后续通过我们的uv.lock进行安装), 所以我们这边首先清除uv cache缓存, 然后再单独创立一个uv环境.
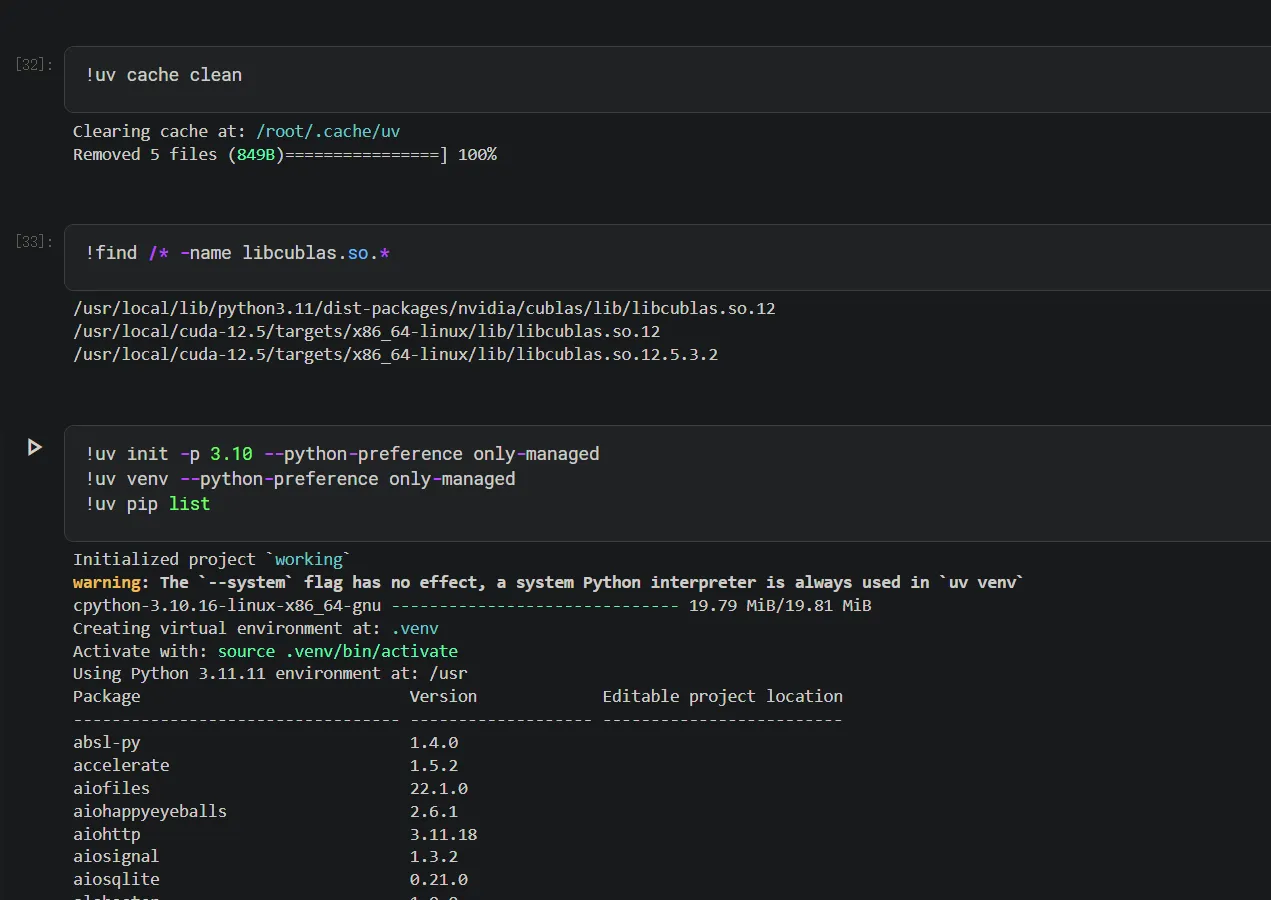
可以看到, 虽然我们尽力指定Python版本为3.10, 但是最终创建的Python虚拟环境仍是3.11.11, 无法准确控制版本, 所以这条路走不通, 只能另寻他法.
GPU服务器(autodl)尝试
看来只能尝试自由度高一点的GPU服务器了, 我使用的是autodl的单卡1080ti(只用来验证uv完全够了, 这是最便宜的). ssh连接上同样查询libcublas.so.*
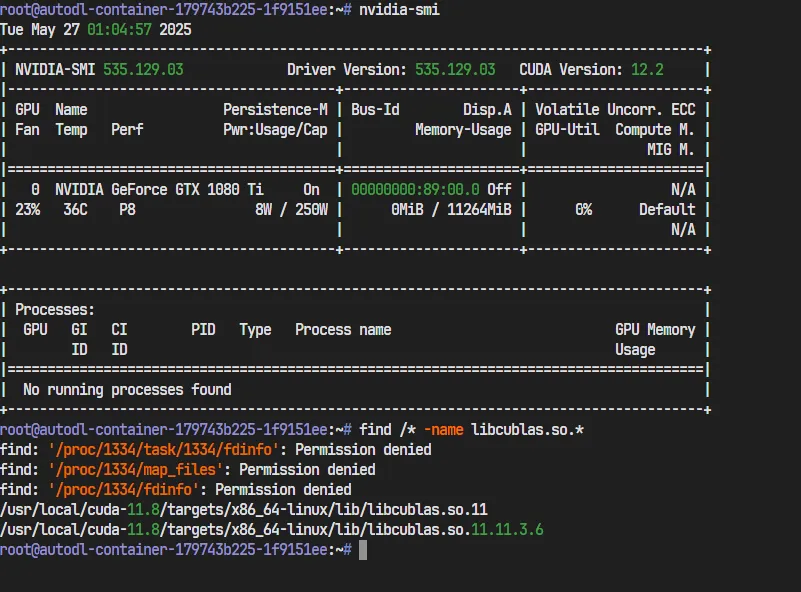
可以看到还是有的, 因为我们需要模拟的是纯净的Docker环境中的uv能否下载CUDA相关包, 所以在这里我们需要删除CUDA.
apt-mark showhold
apt-mark unhold <package>
sudo apt-get remove cuda-toolkit-11-8 # 或你安装的主要toolkit版本
sudo apt-get autoremove
sudo apt-get purge cuda* # 清理配置文件
现在寻找libcublas.so.*就找不到了. 于是我们可以开始正式操作
开始实验
Linux端
我们先从Linux端开始进行实验.
包含NJU镜像
我们将测试项目通过git clone到autodl服务器中, 并安装uv, 之后使用命令uv sync -n --locked进行环境同步.
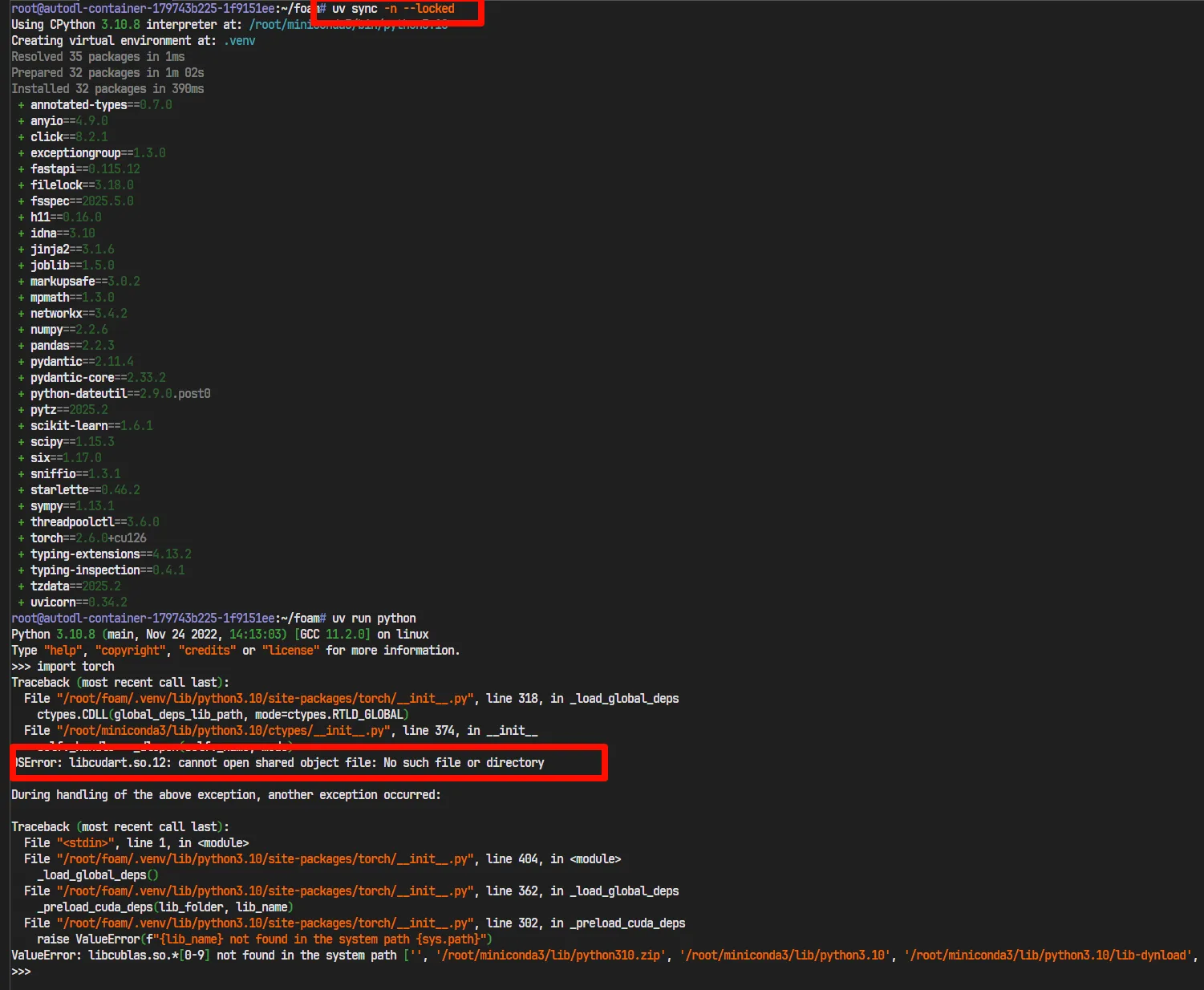
可以看到, 果然是报错了. 而这个时候的pyproject.toml是包含nju镜像的.
[project]
name = "foam"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"fastapi>=0.115.12",
"pandas>=2.2.3",
"scikit-learn>=1.6.1",
"torch==2.6.0+cu126",
"uvicorn>=0.34.2",
]
[[tool.uv.index]]
name = "bfsu"
url = "https://mirrors.bfsu.edu.cn/pypi/web/simple"
[[tool.uv.index]]
name = "pytorch"
url = "https://mirror.nju.edu.cn/pytorch/whl/cu126"
[[tool.uv.index]]
name = "nju"
url = "https://mirror.nju.edu.cn/pypi/web/simple"
[tool.uv.sources]
torch = { index = "pytorch" }
torchvision = { index = "pytorch" }
torchaudio = { index = "pytorch" }去除NJU镜像
我们尝试在pyproject.toml中去除掉NJU的镜像, 删除原来的uv.lock之后使用uv sync.

我们尝试在pyproject.toml中去除torch</mark>2.6.0+cu126, 并手动指定uv add torch<mark>2.6.0
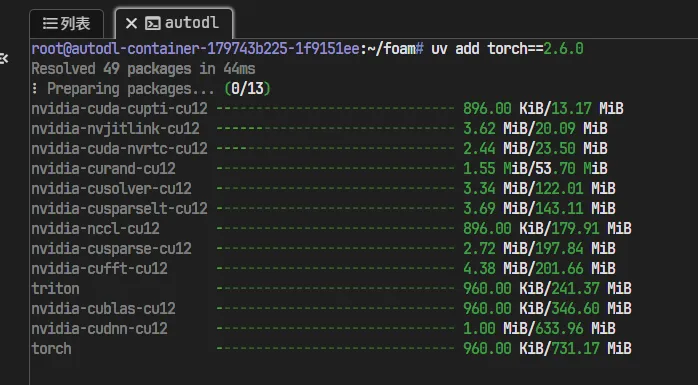
进入Python看torch与CUDA是否正常:
我们尝试运行程序看看是否真的正常:
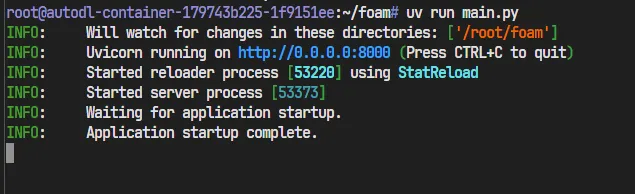
程序也是运行正常的!
至此我们可以得出结论. 在Linux中我们不需要单独对Pytorch的源进行特殊设置, 只需要根据情况设置Pypi镜像源即可, 即使系统中没有CUDA环境, uv也会自动下载cuda相关包.
Windows端
接着我们来进行Windows端的实验.
包含NJU镜像
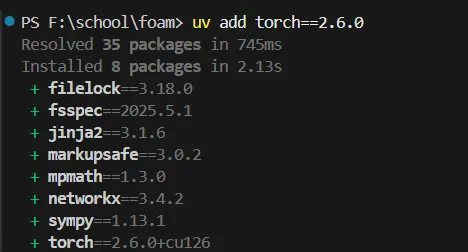
可以看到添加的是cuda版本的torch
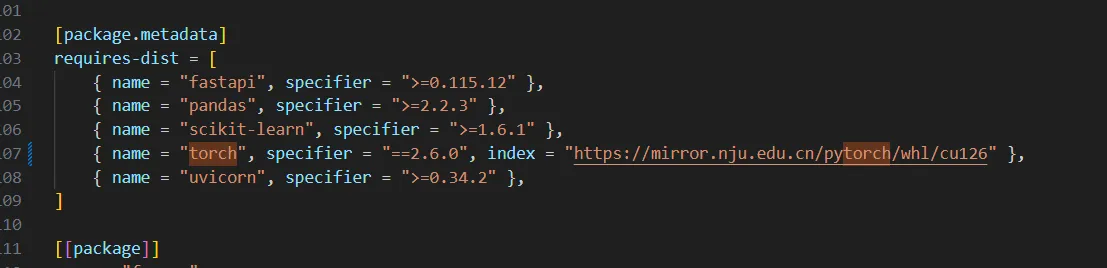
从uv.lock也可以看出来torch确实是走的NJU镜像.
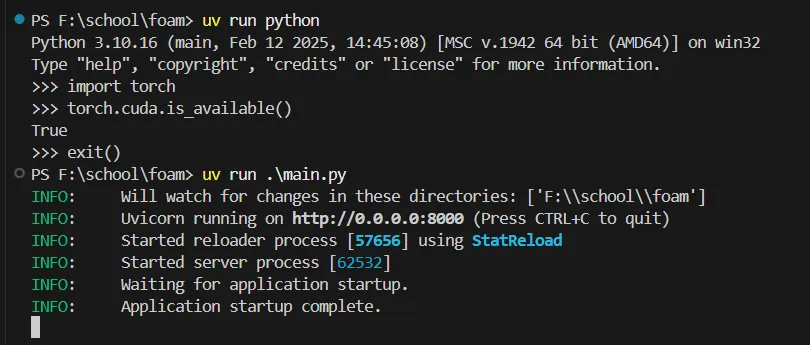
从上图来看运行也是正常的.
去除NJU镜像
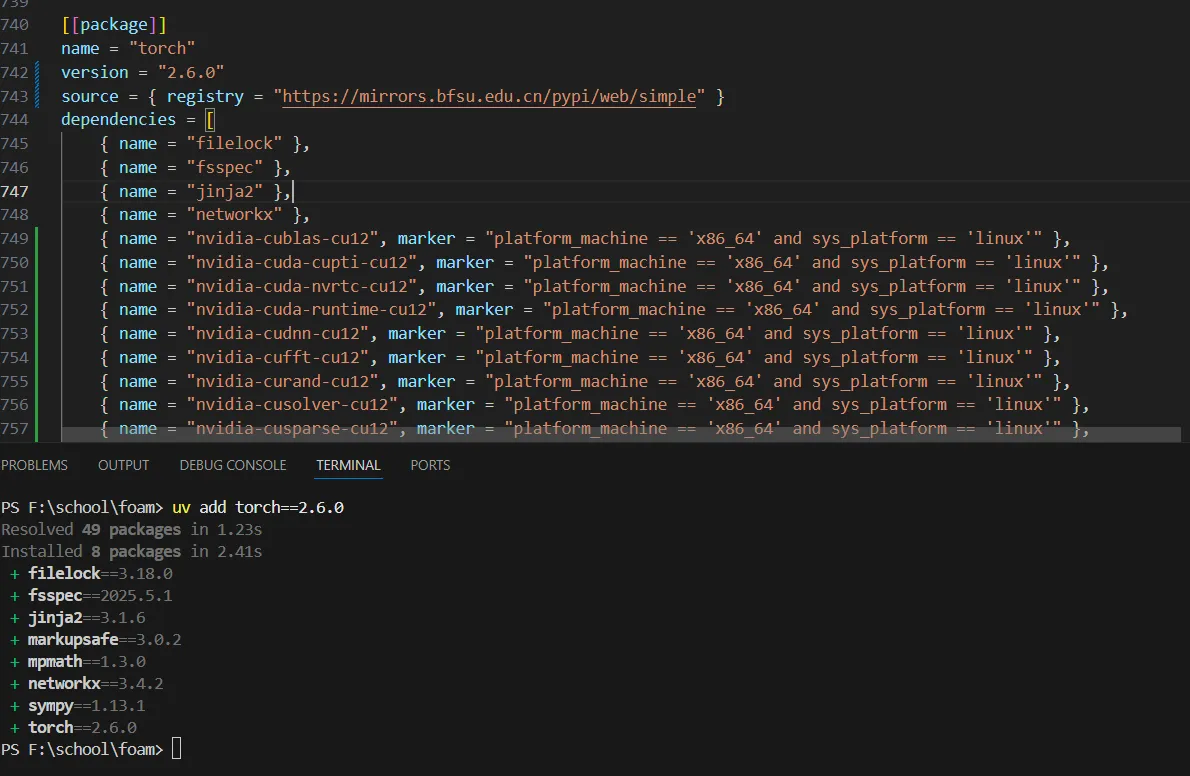
可以看到此时的torch没有cu126标志, 且走的是正常(bfsu)的镜像.
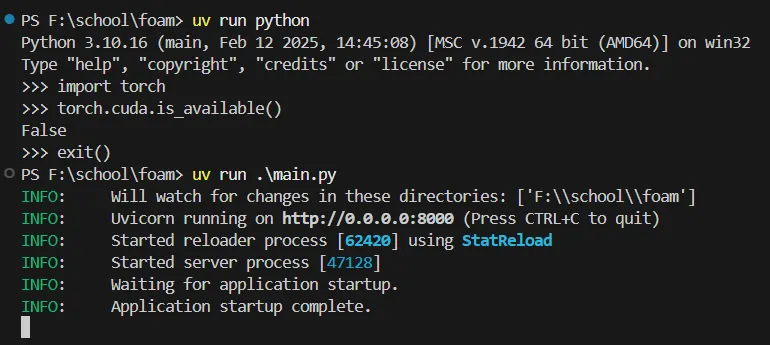
可以看到虽然torch运行正常, 但是并未正常使用GPU. 所以是CPU版本的torch.
NOTE这里我遇到了一个问题, 在运行过程中, 前面一次尝试的时候显示的是True, 但是正式截图这次显示的是False. 我不确定两次是否输入了不同命令, 现在的怀疑是uv sync的问题. 这个问题有待进一步分析与发现.
另外需要说明的是, Windows端事先安装过CUDA驱动, 所以无法保持Linux那样的”纯净”环境. 实验不够严格. 也需要后续有时间的时候进一步实验
实验结论
经过上面的实验, 我们可以初步得到一个结论:
Linux端不需要单独加Pytorch镜像源, 而Windows必须加.== 落实到最佳实践中, 我觉得应该是分为两个分支, 一个开发分支, 一个main分支, 分支的区别在与pyproject.toml上面是否添加Pytorch镜像源.