关于UV管理Python项目以及Docker打包的最佳实践探讨
难以忍受的Conda
目前我在使用uv对python以及项目进行管理, 尝试彻底摆脱conda/mamba的控制. 抛弃它们主要有几个原因:
- 实在是太重了, 一个
conda环境, 如果加上Pytorch的话轻轻松松过5G. 而且Conda对于每个环境是完全隔离的, 新的wheel, 新的包. 对于实验室的代码来说. 我觉得完全可以使用软/硬链接的方式来节省空间 - 速度太慢了, 拿到别人的代码, 在编码良好,
requirements.txt维护良好的情况下, 首先需要创建虚拟环境, 然后安装依赖(如果requirements.txt里面没有固定版本的话也容易出问题). 虚拟环境的创建速度以及安装依赖前的索引查找时间特别漫长. 后面我尝试使用mamba, 号称通过C++重写逻辑, 可以做到和Conda完全兼容. 速度是快了特别多, 但是仍然不够快. - 复现难度高, 就想前面第二点说的那样, 拿到了别人的代码, 可能还需要口述自己的
Python版本, 还有所用的版本等等. 不过对于大部分情况, 项目的requirements.txt都没有维护, 往往是发给别人的时候才匆匆使用pipreqs或pigar来扫描代码(或者更加传统的一个一个人工看), 生成依赖. 这种方式不仅增加无谓的工作量, 且不太准确.
综上所述, 我一直在忍受着Python生态/项目的凌乱. 对于热衷于寻找各方面”最佳实践”的我来说, 当我听到uv的时候, 毫不犹豫的进行了尝试, 结果很令人欣喜, uv在很大程度上解决了上述的问题(虽然引入了一些新的问题). 当前的问题跟uv本身带来的学习成本和问题相比不值一提. 我觉得以后实验室内如果大家都用uv且有良好的代码习惯, 对于工作效率的提升是巨大的.
uv带来的优点
针对上面三个问题, 我们来一起梳理一下uv的解决方式.
针对
Conda笨重的问题,uv采取轻量化的操作, 能不预装的都不装(干净程度可以理解为pyvenv). 而且uv支持多种LINK_MODE对依赖进行管理."clone": Clone (i.e., copy-on-write) packages from the wheel into thesite-packagesdirectory"copy": Copy packages from the wheel into thesite-packagesdirectory"hardlink": Hard link packages from the wheel into thesite-packagesdirectory"symlink": Symbolically link packages from the wheel into thesite-packagesdirectory
简单来说, 就是可以通过软硬链接的方式来节省空间(这里插一嘴, 硬链接必须要求依赖缓存与项目目录在同一文件系统内). 平时使用短链接即可大幅减少硬盘空间占用. 就算
symlink也出现问题, 还会自动退化到copy, 保证可用性.不过需要注意的是, 当使用软链接的时候, 如果清除了
uv_cache, 这个时候项目是跑不起来的(源文件都没了😂)针对
Conda太慢的问题,uv使用rust进行重构, 在保证功能性的同时, 大幅加快速度, 真正做到”快到飞起”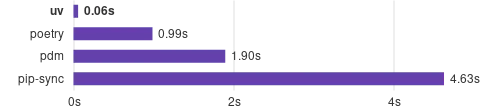
uv速度 针对”复现难度高”的问题,
uv的实现类似于前端包管理工具, 通过pyproject.toml(类似于package.json)确定包版本, 以及一些自定义配置. 同时使用uv.lock(类似npm.lock/pnpm.lock)等唯一确定当前使用的依赖版本, 确保可以复现.具体来说,
pyproject.toml中的依赖是可以不手动添加的, 只需要使用uv add <package>,uv会自动解析依赖并添加对应的信息到pyproject.toml和uv.lock中.通过这种方式, 真正做到了, 只要都是相同的系统(都是windows), 只要A能跑得通, B一定能跑通(除非有bug). 看我前面打了这么多补丁, 想必也知道这就是之前说的uv带来的问题了
uv的简单使用
前面说了这么多, 这一节具体说说uv的基本使用.
前置配置
以前我有严格的代码/文件洁癖, 不希望出现任何未经允许的在
home目录(对应windows的C:/Users/XXX)存放文件. 但是后面我在写小软件的时候, 也喜欢往这里放🤣(代码里面东西存在home目录确实方便好写不容易出现bug). 后面心态逐渐放开了, 允许一部分小软件放在C盘, 不过什么缓存之类的坚决不能放在C盘.
安装
uv安装
uv只需要一行命令即可:# On Windows. powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"虽然也有其他方式, 比如通过
pip安装, 但是有pip一般都有Python环境, 而且无法确定这个Python环境是否是虚拟环境, 如果是在Conda虚拟环境里面装的uv的话, 后续的使用过程中可能会造成混乱. 所以我个人确定的最佳实践就是: 删除代码中现有Python环境/Conda等. 保持系统的纯净, 然后使用上述命令安装uv设置环境变量
uv全局上通过uv.toml或环境变量进行配置. 在Windows上的话使用环境变量配置会更加方便一点(因为我现在也没搞懂uv不同路径下配置文件的优先级)有那么几个重要的环境变量需要配置:
UV_CACHE_DIR:uv包缓存路径, 这个一定要设置, 不设置的话就放到C盘去了UV_DEFAULT_INDEX:uv下载镜像源(同pip镜像源)UV_LINK_MODE:uv新项目中的依赖放置方式, 一般来说硬链接(hardlink)性能是最好的, 但是之前说了,硬链接的前提是uv项目路径和UV_CACHE_DIR出于同一个文件系统(同一个盘符). 因为不同文件系统的文件组织方式不一样, 而硬链接是通过指向相同inode来实现的.UV_PYTHON_INSTALL_DIR:uv管理的Pyhton不同版本放置目录.
一般设置以上这些环境变量之后就可以进行使用了
常用命令
uv有以下常见命令, 本节从新建一个目录开始, 以时间顺序讲起.
uv python install <version>: 使用uv安装指定版本的Python. 这一步并不是必须的, 后面创建项目的时候发现没有对应版本的Python,uv会自动去下载.uv init -p <version>: 初始化项目并指定Python版本. 使用这个命令会默认创建以下几个文件:- .python-version: 用于标明项目使用的Python版本
- main.py: 示例代码
- pyproject.toml: 项目配置文件, 可以在里面定义镜像源, 依赖, 构建等配置
- README.md: 项目文档
uv venv: 创建虚拟环境. 使用该命令会读取定义的Python版本并生成.venv目录. 至此项目便可以使用该虚拟环境进行开发了.uv add <package>: 安装依赖.uv remove <package>: 删除依赖(在项目中删除, 实际的包缓存在UV_CACHE_DIR)uv pip xxx: 这是一系列命里, 支持常见的原始pip xxx命令, 只需要在前面加上uv即可.uv run xxx.py: 效果同python xxx.pyuv sync: 根据pyproject.toml里定义的依赖进行环境同步. 不过默认应该是懒加载.uv sync --locked: 这一条必须要单独拎出来说, 是否--locked的区别在于是否严格按照uv.lock里面固定的版本和源进行环境同步. 不加locked的话默认会去寻找最新版, 之前就是因为这个导致无法正常安装依赖. 如果是别人的项目需要进行同步的话, 一定要加上—lockeduv lock: 固定当前的依赖, 生成uv.lock文件. 不过一般都会自动生成, 不需要去过多干预.
以上就是使用过程中最最常用的命令, 足够日常使用了. 如果遇到了其他问题, 自行搜索即可.
pyproject.toml内常用配置
目前我对uv的使用尚不深入, 并没有构建成package的需求. 所以本节仅讲述我使用过的一些pyproject.toml配置.
刚初始化项目的时候, pyproject.toml结构是这样的:
[project]
name = "test"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.10"
dependencies = []我们尝试安装一个numpy, 查看其变化:
[project]
name = "test"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"numpy>=2.2.6",
]
[[tool.uv.index]]
url = "https://mirrors.bfsu.edu.cn/pypi/web/simple"
default = true可以看到dependencies里面自动写上了numpy和版本, 所以说对于简单依赖, 我们是不需要去手动维护的(除非我们需要指定一个非常明确的版本范围等).
另外还可以看到, 还生成了对应的源链接. 这是因为我们的环境变量(UV_DEFAULT_INDEX)在起作用.
对于一些只在开发过程中用到的依赖, 比如pipreqs, 我们可以在add命令上加上—dev, 即可生成dev的依赖(同npm/pnpm)
[project]
name = "test"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"numpy>=2.2.6",
]
[[tool.uv.index]]
url = "https://mirrors.bfsu.edu.cn/pypi/web/simple"
default = true
####### 注意看这里 #######
[dependency-groups]
dev = [
"pipreqs>=0.5.0",
]这里值得说明的是, torch的gpu包并没有放在pypi索引中, 所以国内的加速源是没法直接通过pip下载到cuda版本的torch的. 需要单独的index才行. 如果不指定的话, 默认会去pypi下载cpu版本.
如果我们需要gpu版本的话, 有以下两个方式:
uv pip install torch<可选<mark>version> --index-url https://download.pytorch.org/whl/cu126(这里的126可以更换, 具体看需求). 通过以上命令先下载torch包. 之后再使用uv add torch<可选</mark>version>进行引入. 不过这种方式需要拥有良好的网络条件.使用南京大学torch的gpu版本镜像源
[[tool.uv.index]] name = "bfsu" url = "https://mirrors.bfsu.edu.cn/pypi/web/simple" [[tool.uv.index]] name = "pytorch" url = "https://mirror.nju.edu.cn/pytorch/whl/cu126" [[tool.uv.index]] name = "nju" url = "https://mirror.nju.edu.cn/pypi/web/simple" [tool.uv.sources] torch = { index = "pytorch" } torchvision = { index = "pytorch" } torchaudio = { index = "pytorch" }在pyproject.toml加上上面的配置, 即可从nju下载gpu版本的torch了.
uv打包Docker的最佳实践
虽然一直没有使用uv构建package, 但是一直有将项目打包为Docker镜像的需求. 本节就来讲讲我摸索到的当前uv打包Docker镜像的最佳实践. 虽然还是有些不优雅, 但是相较于Conda已经很不错了.
不涉及GPU加速的uv项目
这里说不涉及GPU加速的uv项目, 其实实际生活中90%的情况专指不涉及torch. 可能只是一些小软件, 小爬虫, API后端等等. 对于这些软件来说, 使用uv打包Docker的过程是比较丝滑的.
以下还是按照时间顺序来进行说明:
创建
.dockerignore, 在里面写上.venv, 用于避免后续Docker构建过程中将虚拟环境也复制进去了.venv创建
Dockerfile, 在里面写上以下内容# 这里可以选择指定版本, 修改python后面的数字即可, 不过仍然建议使用bookworm-slim而不是更精简的apline, 主要是为了避免缺少一些系统运行库. # 不过在确保可运行的前提下追求更小的镜像大小仍是好的 FROM ghcr.io/astral-sh/uv:python3.10-bookworm-slim # 设置工作目录 WORKDIR /app # 复制项目文件到工作目录, .dockerignore就是为了避免这一步复制.venv COPY . . # 使用 uv sync 安装依赖 # 这会根据 pyproject.toml 或其他配置文件同步并安装依赖项 # -n参数是不保留依赖缓存的意思, --locked的意思是严格依照uv.lock进行同步 RUN uv sync -n --locked # 指定容器启动时运行的命令 CMD ["uv", "run", "main.py"]五行命令, 即可丝滑启动. (以上代码基于API服务端的启动方式)
涉及GPU加速的uv项目
涉及到GPU加速, 即大概率涉及到torch, 这下就变得些许丑陋, 没那么优雅了. 以下同样按照时间顺序进行说明:
确定自己需要的Python, Torch, CUDA版本, 到Dockerhub的Pytorch页面寻找对应的tag. 例如我们想寻找2.6.0的torch

Dockerhub中Pytorch界面截图 尝试优先级为: runtime > devel. 个人认为镜像大小的重要性还是比尝试构建的时间要更加重要.(特别大的Docker镜像遇到小水管的时候就老实了)
复制右边的命令, 并Pull下来. 这里选择直接Pull下来而不是放在Dockerfile中, 主要是出于构建缓存的考量, 直接Pull下来的话不会收到清除构建缓存的影响.
创建Dockerfile
# 这里选择刚刚下载的Pytorch镜像版本 FROM pytorch/pytorch:2.6.0-cuda12.6-cudnn9-runtime # 设置工作目录 WORKDIR /app # 复制项目文件到工作目录 COPY . . # 使用 pip install 安装依赖, 这里是相较uv比较丑陋的地方, 需要自己把依赖从pyproject.toml里面抽出来 RUN pip install --no-cache-dir fastapi>=0.115.12 pandas>=2.2.3 scikit-learn>=1.6.1 uvicorn>=0.34.2 # 指定容器启动时运行的命令 CMD ["python", "main.py"]同样五行代码, 虽然不是丝般顺滑, 但是依旧简洁明了.
但是值得说明的是, 这个Docker镜像会很大, 大概是4-7G的量级, 不过谁叫沾上CUDA了呢
uv sync中的”坑”
虽然看上面的最佳实践感觉比较顺, 但是这些都是我踩了许许多多的坑总结出来的. 于是单开一节, 讲讲最近遇到的有关uv和torch的坑.
还是从时间顺序说起吧, 希望能提供一些思路和线索.
问题显现
一切还得从上面的torch(gpu)说起. 本来我也是打算使用第一种uv sync -n --locked的方式进行构建的,
不过在构建的过程中就报错了:
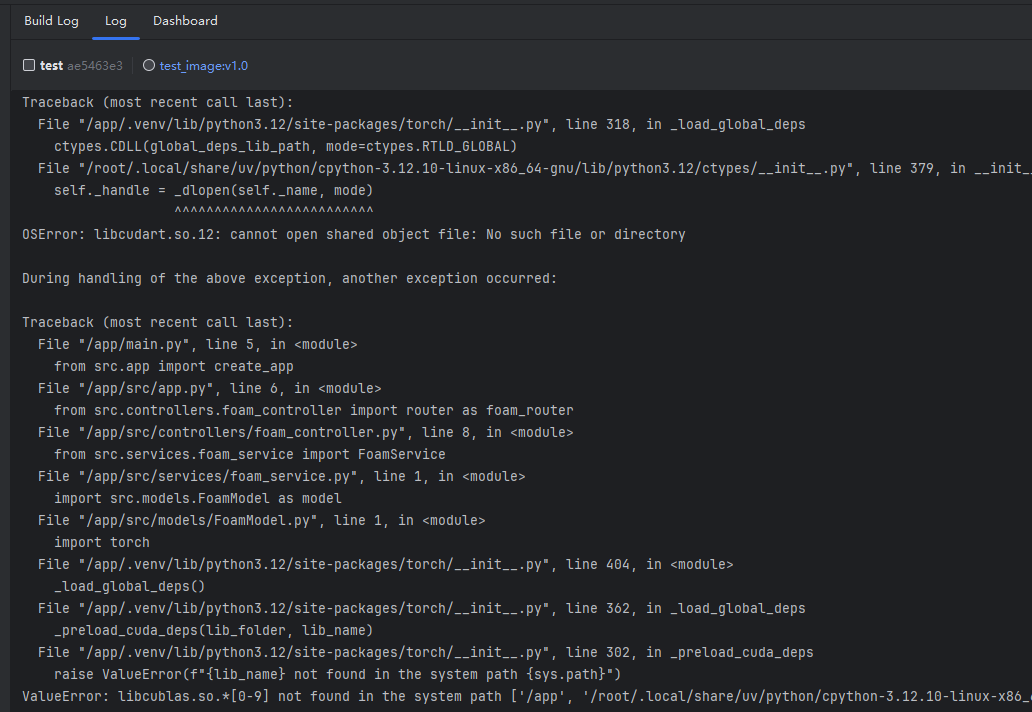
显示没有libcudart.so.12, 百思不得其解. 后面我尝试更换Python版本和torch版本, 也是一样的报错.
初步尝试
后面我考虑是否是镜像源的问题, 导致有些依赖包没有安装上, 于是使用原版Pytorch镜像源, 但还是报错且报错信息一样.
至此, 我们能够基本排除是镜像源导致的问题. 所以我索性将pyproject.toml里面的镜像配置全部删除, 之后进行构建. 马萨卡, 没想到居然能跑了!
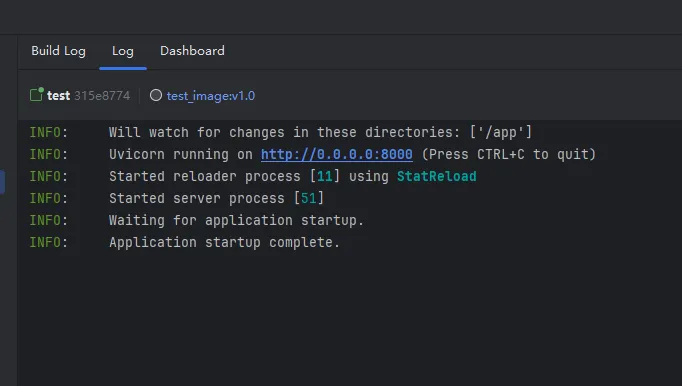
于是我开始寻找这个问题的源头, 难道还是因为镜像源?
问题分析
我尝试对前(含有nju镜像)和后(去除所有镜像)的uv.lock进行对比分析, 发现了一个华点:
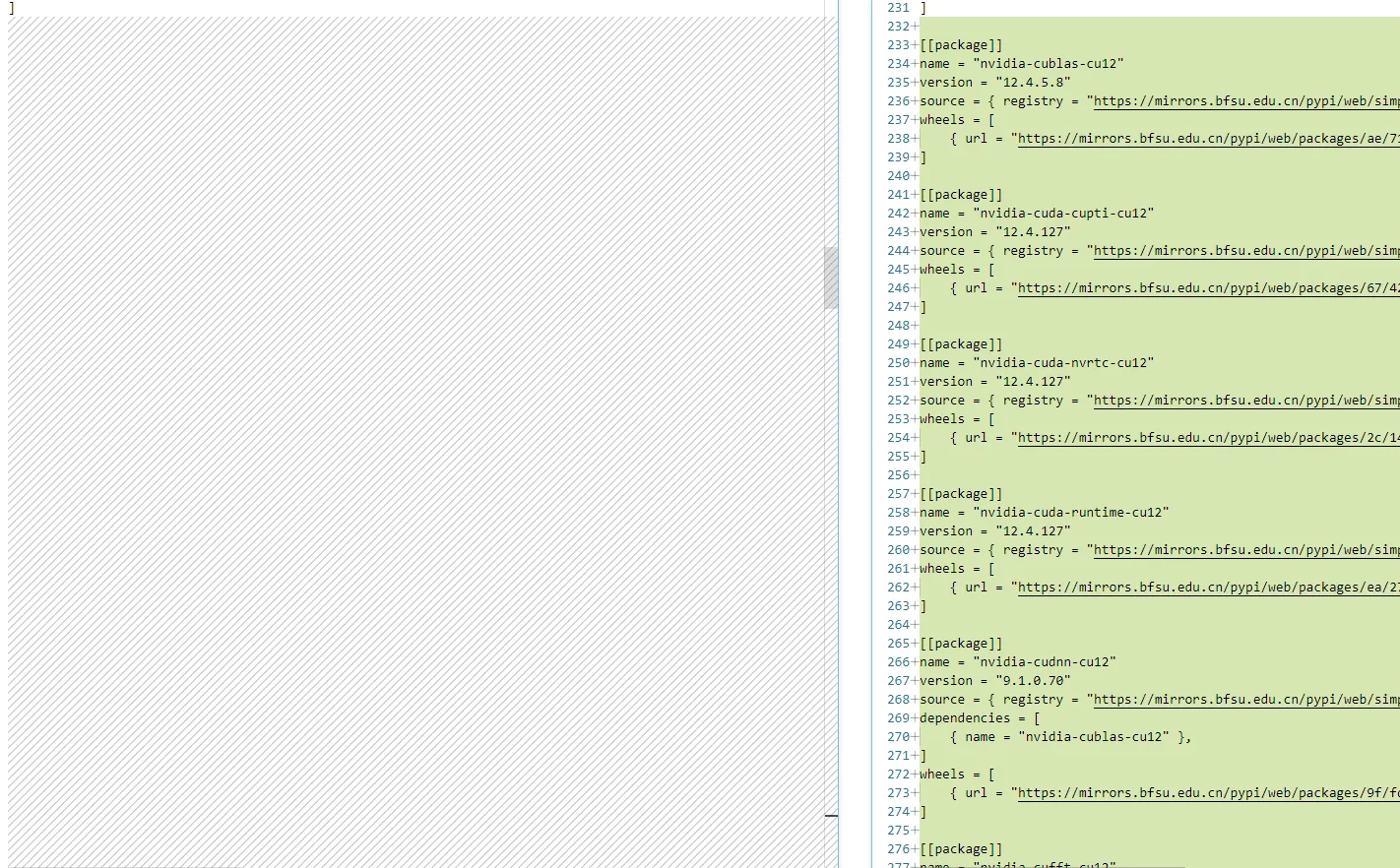
可以看到去除所有镜像之后的uv.lock会多很多有关cuda的依赖, 而这些依赖的连接都带有manylinux, 没有win32, 这也就意味着, windows端没有这些包.
我们再来梳理一下思路. 首先, 使用nju镜像, 会缺少有关cuda的依赖包, 但是可以正常运行, 因为有关cuda的那些库已经装过了. 而linux版是可以通过pip的方式安装这些cuda依赖包的. 所以我拿nju镜像的uv.lock(缺少依赖)到Docker里面构建, 会缺少安装cuda依赖, 从而导致运行报错. 而去除了nju镜像之后, windows端会从pypi(bsfu源)下载cpu版本的torch.
不过这里还有一个奇怪的点: 为什么windows不配置pytorch源, 使用uv add torch下载的是cpu版本, 而linux就下载的gpu版本?
先搁置上面的问题, 所以现在部署的最佳实践是:
对于Docker部署, 使用新分支, 在这个新分支中去除所有源设置, 并运行uv sync生成新的uv.lock. 根据这个新的uv.lock来进行后续的部署操作. 这样的话就可以参照不涉及GPU加速的uv项目进行Dockerfile的编写了.